

Inference is FREE and INSTANT
Do not count on LLMs getting smarter

It seems that people have been polarized into two opposing outlooks on the future of AI - more specifically, large language models (LLMs). Some say everything will look very different six months from now. Others think we've just hit the point where throwing more compute and data yields diminishing results. I must confess, I'm closer to the latter perspective.
Now you might be thinking, "But you're literally betting your life on LLMs. You dropped out of college to build an LLM codegen application." Yes, but with an asterisk: Fume isn't built on the premise that LLMs are going to get substantially smarter in the coming months. Instead, we're certain they're going to get much cheaper and faster. So, when building Fume, we assume inference is free and instant - even if both statements are painfully false at the moment.
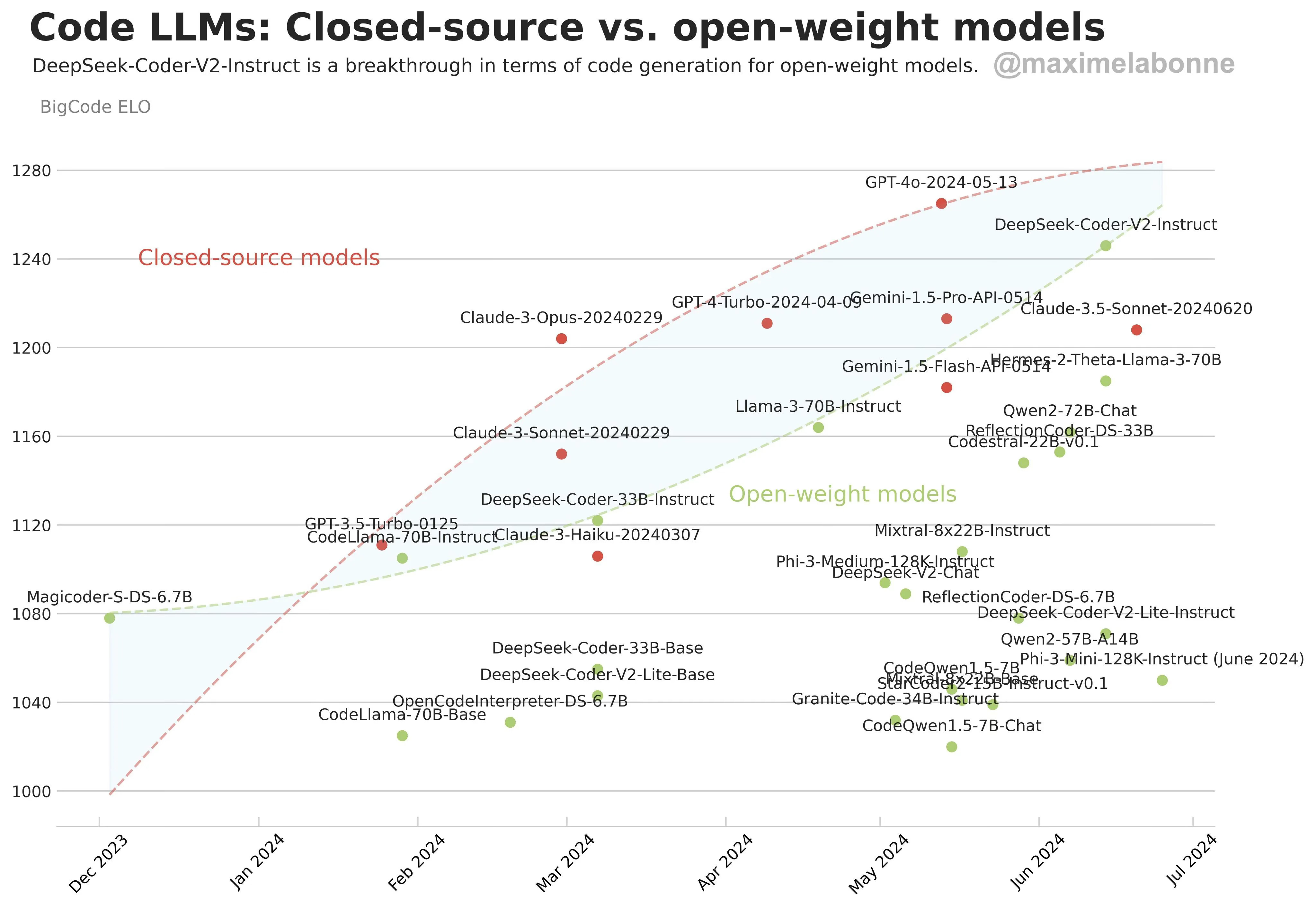
This famous graph in the Twitter AI circle shows the LLMs' reasoning progression over time. As clearly seen, the exponential pattern is quickly lost for closed-source models, and I believe the same will happen to open-source ones too (they're usually one step behind).
The y-axis BigCode ELO score is an imperfect way to measure reasoning capabilities. However, I think it's a good representation of the general experience of using everyday LLM tools like ChatGPT or Claude. They simply haven't gotten wildly better over time.
The important point here is that we don't seem to be on an exponential trajectory when it comes to reasoning capabilities. I might be happily proven wrong if OpenAI unveils a revolutionary model with Strawberry, Q*, or whatever codename they choose. Even if not, I don't think this is scary. Exponential trends are extremely rare.
I believe there is one emerging exponential trend in the LLM field: Price. The cost of LLM inference has been exponentially decaying since the early days of the technology. Here's a comparison between one of the earliest publicly available GPT models and current state-of-the-art models:
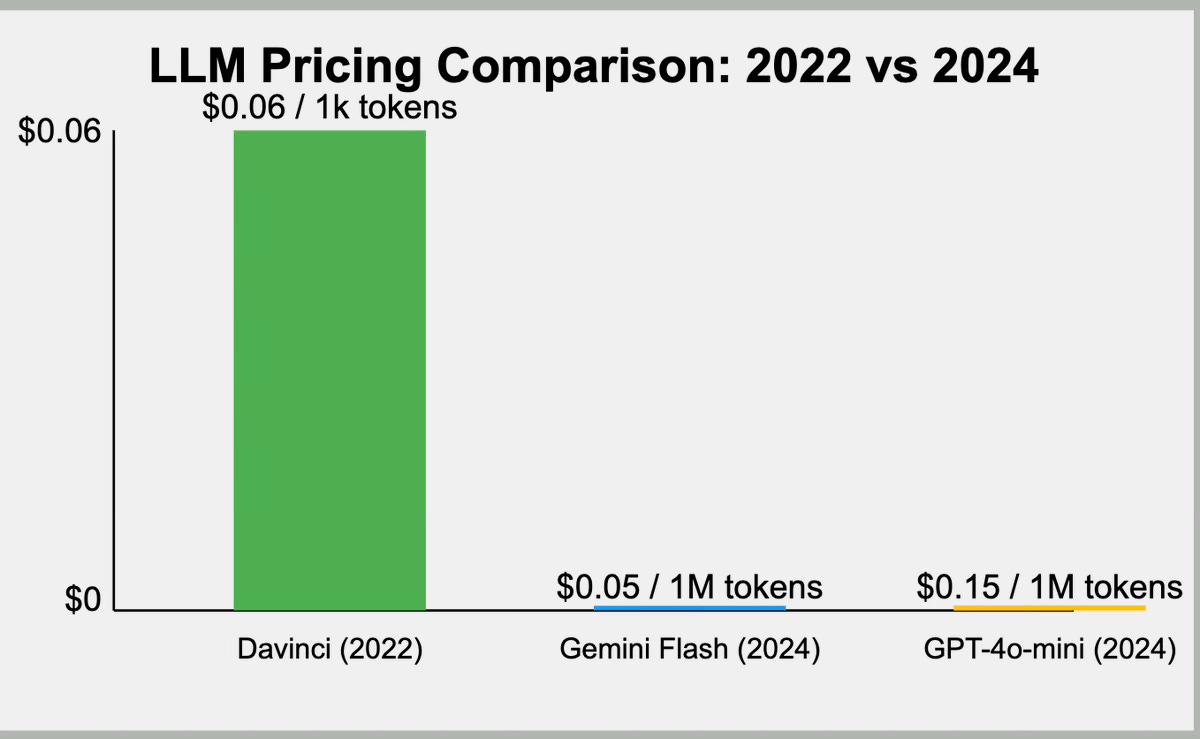
I wish I could find a better graph to show the trend, but judging from the recent updates from leading model providers (OpenAI, Anthropic, and Google), they've been constantly coming up with cheaper and faster models that match the capabilities of previous biggest and smartest models (e.g., GPT-4, Claude 3.5 Sonnet).
In my humble opinion, these companies would not allocate a second of compute to lightweight models if they thought there was a straightforward way to achieve the next leap in reasoning capabilities.
The speed argument is almost a natural consequence of LLMs getting more optimized and cheaper, so I won't explain it in depth.
The Chinese Room Argument
This brings us to the famous thought experiment from John Searle: the Chinese Room Argument. This argument is designed to challenge the notion of **strong artificial intelligence**.
In the thought experiment, Searle imagines himself as a monolingual English speaker locked in a room. He's given a set of Chinese characters, a dictionary, and a manual that instructs him on how to respond to Chinese questions by manipulating these symbols. Despite being able to produce responses that appear fluent in Chinese, Searle doesn't understand the language; he's merely following syntactic rules without grasping their semantic meaning.
Now imagine if Searle could move at the speed of light.
No matter how fast Searle is, he won't be able to come up with a beautiful and original Chinese poem that has the creative spark special to humans. But he could be pretty darn useful when I want to fill out some boring forms to apply for a Chinese visa.
In our view, Fume is in a similar situation with a computer in its room. There's no way Fume will come up with a creative solution to your problem if that solution isn't in the book (in this case, the book is the data on the internet about software development). But it can be very useful when it comes to handling the everyday grunt work of software development. Even if LLMs don't get any smarter, Fume can look up the book, code, test, and repeat infinitely until it works. Of course, at some level of complexity, it will be stuck in a local maximum of work quality simply because the book has no guide on how to solve the problem at hand.
Our job is to build the perfect workflow for Fume, so the maximum complexity of tasks it can solve is as high as possible. The closer Fume gets to operating at the speed of light, the more creative we can get with the workflow. Right now, Fume can solve UI issues, simple bugs, code refactoring, etc. In the future, it might be able to do a sprint's worth of work in an hour, but an engineer will still have to tell Fume what to work on. Nevertheless, it's pretty darn useful.